作者:Nick Bryan | Jason Segall
在运行生物测定时,我们面临着两个相互竞争要求之间持续不断的斗争。测定必须能够检测到实验或产品何时出现问题,但同时,也不能过于灵敏,以至于由于生物测定中固有的生物学自然变异性而频繁失败。实现这种精细平衡的关键在于对适用性标准做出战略性选择,包括检验的选择和失效阈值的设定。在这里,我们将重点介绍我们在 20 多年的生物测定咨询经验中遇到的一些常见陷阱,以帮助您优化下一个生物测定。
什么是适用性标准?
适用性标准大致可分为两类:系统适用性标准和样品适用性标准。
系统适用性标准
系统适用性标准检验测定本身是否按预期运行。这些标准包括对参比品或 QC 样品的拟合优度等性质的检验,或对 QC 样品相对效价的检查,以确定测定的偏差是否可接受。如果测定未通过系统适用性标准,则通常需要对整个测定进行重复。
样品适用性标准
样品适用性标准适用于单个测试样品,旨在确保这些样品按预期行为表现。样品适用性标准的示例包括平行性检验或相对效价估计值的精密度标准。如果样品未通过其适用性标准,则只需重复该样品:同一测定中通过样品适用性的其他样品的数据可视为有效。
通常,所有测定都需要系统适用性标准和样品适用性标准。为测定选择哪些标准会对测定的失败率产生显著影响。我们总是希望确保测定的失败率尽可能小,因为任何测定失败都可能成为代价高昂的时间和资源浪费。因此,让我们看看由于适用性标准选择不当而导致测定失败率不必要地增加的一些常见方式。
核心要点
- 生物测定需要系统适用性标准(测试测定性能)和样品适用性标准(测试单个样品)以确保有效性,但两者都必须精心选择,以尽量减少不必要的测定失败。
- 使用过多的标准、选择测量同一性质的相关检验,或设置不恰当的阈值或检验(例如,在极高精度测定中使用 F 检验,或使用不合适的参数比值),会显著且不必要地增加测定失败率。
- 限制检验数量、避免冗余或不恰当的标准,以及考虑使用等价性检验或参数差值代替比值等替代方案,可以优化测定性能并减少资源浪费。
过多的适用性标准
在测定中塞入大量检验可能很有诱惑力:更多的检验难道不意味着你对自己的结果更有信心吗?不幸的是,在适用性检验中,并非越多越好。
每当我们使用统计检验时,总是存在一定的概率,即检验会仅因随机变异性而失败。这被称为 I 类错误,是任何检验定义的关键组成部分。例如,当我们定义一个显著性检验的显著性水平为 5% 时,我们可以解释为:该检验平均会有 5% 的时间因偶然因素而失败。
那么,假设我们运行一个测定,所有适用性标准都使用显著性水平为 5% 的检验进行测试。如果只有一个检验,我们预计每 100 次测定中会有 5 次因偶然因素而失败——这还算可以接受。然而,如果我们添加第二个检验,测定因偶然因素失败的概率就会增加到 9.75%(假设检验结果是独立的——更多内容见后文)。任何单个检验失败的概率仍然是 5%,但任何检验失败的概率却增加了:我们问的是”检验 1 或检验 2 失败的概率是多少?”
因此,如果我们使用 5 个检验,那么我们测定仅因偶然因素失败的概率就会突然超过 20%!这还不包括由测定真正问题导致的失败。这显然是不可持续的。因此,至关重要的是,我们的检验数量不应超过确保测定正常运行所需的数量。
相关的适用性标准
在为测定设定适用性标准时的另一个考虑因素是,多个检验是否——可能无意中——在同时测量同一件事。我们称这些检验为相关的,因为它们往往会在同一测定中同时通过或同时失败。
一个示例可能是基于比较测试样品和参比标准的模型参数的平行性检验。我们已经在其他地方详细讨论了平行性,但简要回顾一下,如果两个 4PL 模型的所有参数除了 EC50 外都相同,则认为它们是平行的。因此,检查测试样品是否表现出平行性的一种方法是对测试样品和参比品的部分或全部模型参数进行检验,以检查它们在统计上是否被认为是相似的。
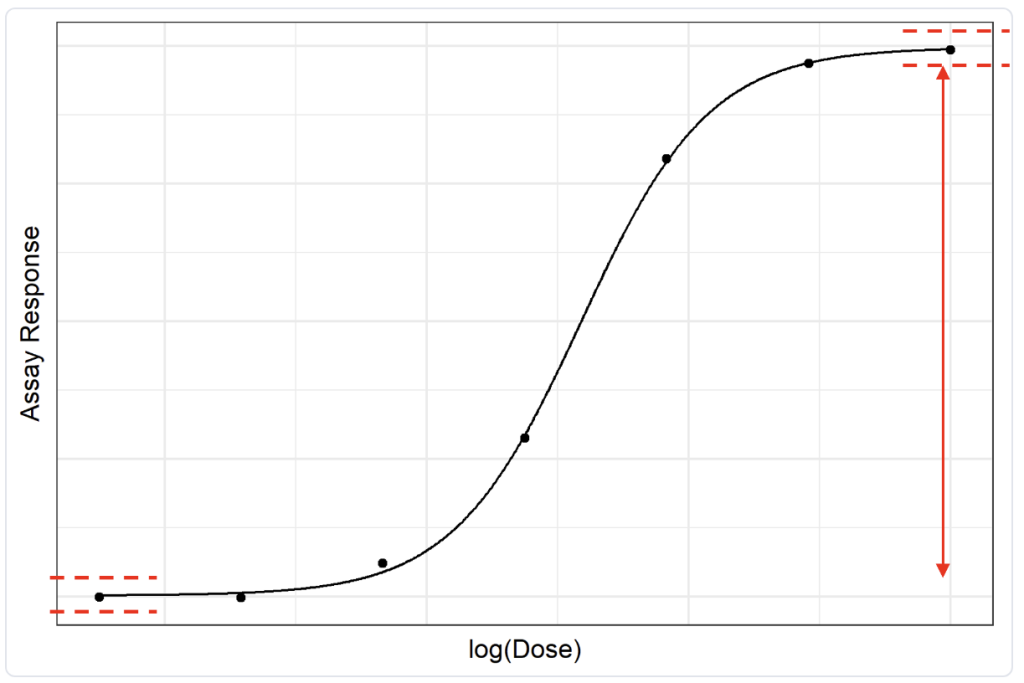
假设您对上下渐近线都设置了这样的检验,同时还对测定范围(即渐近线之间的差值)设置了检验。这将是一个相关检验的示例,因为测定范围本质上是由上下渐近线定义的。如果测试样品的范围与参比品的不同,那么几乎可以肯定至少有一条渐近线也不同,这意味着两个检验很可能同时失败。
在这种情况下,我们或许可以考虑只对测定范围和其中一条渐近线设置适用性标准。这意味着我们仍然以与之前相同的严格程度检查样品的相似性,但只使用两个检验而不是三个,同时也节省了时间和资源。
不恰当的适用性标准
这可能是我们在客户生物测定中看到的不必要升高的失败率的最常见原因。如果适用性标准设置了不恰当的限值、选用了不合适的参数或参数组合,或使用了错误的统计检验进行检查,那么测定可能会因此导致失败率大幅上升。
一个常被引用的例子是在非常精密的测定中使用 F 检验,无论是用于检验系统适用性的拟合优度,还是用于检验样品适用性的平行性。正如我们之前所讨论的,F 检验旨在确定数据围绕拟合模型的散布中有多少是源于自然变异性,又有多少是源于模型拟合不佳。它通过比较剂量组的纯误差(每个重复到重复均值的总距离)与失拟误差(剂量组重复均值到模型线的距离)来实现这一点。
对于非常精密的测定,纯误差总是很小,这意味着失拟误差将占主导地位。这可能导致测定未通过 F 检验,即使从任何其他衡量标准来看,我们都期望它通过。
什么迹象表明 F 检验可能不适用于您的测定?如果您预计测定将有很高的精密度——例如,如果您使用机器人进行测定点样——那么最好避免使用 F 检验。另一种情况是当您使用伪重复时,这会由于相关性而降低重复的变异性。在一项模拟研究中,我们表明,强相关的重复在 F 检验的拟合优度测试中表现出高达 99% 的失败率,这意味着在这种情况下,该检验是一个特别糟糕的选择。
如果您有足够的历史数据,那么使用等价性检验而不是像 F 检验这样的显著性检验是一个不错的选择。虽然这在统计上设置起来更复杂,但它规避了围绕 F 检验的精密度问题。另外,当没有测定可用的历史数据时,使用”下一个模型”的检验可以是评估模型适用性的一个解决方案。例如,如果您使用的是 4PL 模型,您可以对数据拟合一个 5PL 模型,并检验 E 参数在统计上是否与 1 显著不同。如果不同,这将证明 5PL 比 4PL 能更好地拟合该数据。如果我们期望数据符合 4PL,那么这可能表明出现了问题。
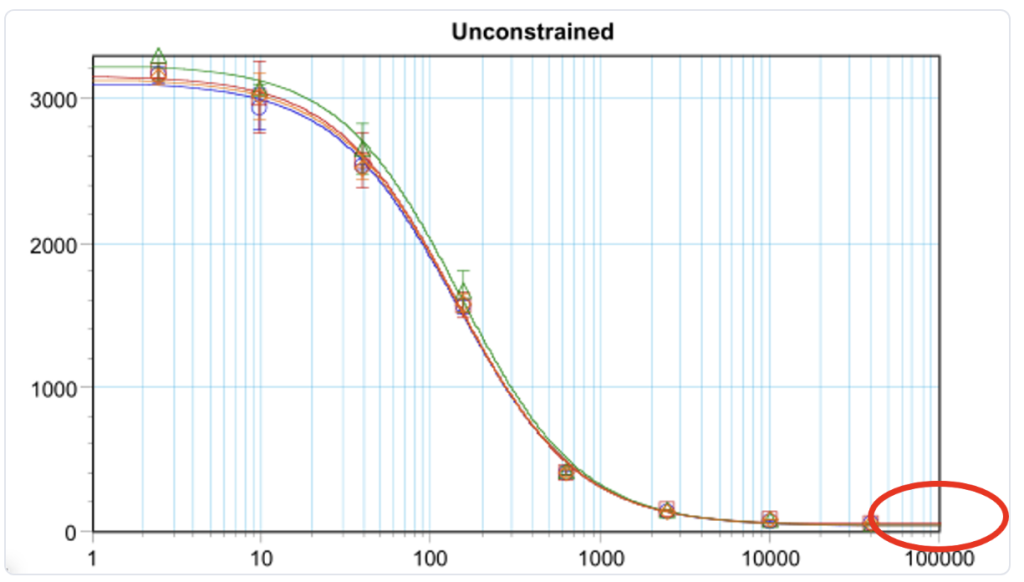
另一个经常被证明不恰当的适用性标准示例是基于模型参数比值的标准,这些标准通常用于检验平行性。如果所选参数的比值接近 1,则表明参比品和测试样品之间存在相似性。然而,如果其中一个参数通常接近零,这可能会带来问题,因为除以一个小数可能会得到一个远大于 1 的结果,即使模型参数之间的差异很小。
这个问题经常出现的一种情况是,测定在低剂量下的响应接近于零。如果选择了基于下渐近线参数比值的适用性标准,那么很可能会由于参数比值而看到不必要的测定失败。因此,我们通常建议使用参数之间的差值而不是比值,因为差值不会像参数比值那样有被放大的趋势。因此,检验参数差值而非比值是避免不必要测定失败的好方法。
继续阅读…
生物测定优化:节省时间,节省金钱如何为相对效价生物测定设置适用性标准R² II:你应该用什么来测量拟合优度?
寻找最优解决方案
生物测定是复杂的实验,需要大量资源——无论是人员方面还是资金方面——才能有效地开发和运行。没有两个测定是完全相同的,这意味着对一个测定而言的最佳解决方案可能会对下一个测定造成无穷无尽的麻烦。尽管如此,我们希望本文中提出的建议能够启发大家思考,如何通过对适用性标准做出审慎选择来优化测定设计。而且,如果您需要任何进一步的指导,Quantics 随时为您提供帮助!
Nick Bryan
Nick 是 Quantics Biostatistics 的资深统计师。他为客户提供 GxP 研究、生物测定设计以及临床和非临床研究分析方面的支持。他曾在 Ipsen Biopharm 和 Sanofi 工作,在生物制品和小分子领域拥有丰富经验。他拥有数据科学与人工智能硕士学位以及神经科学学士学位。
Jason Segall
Jason 于 2022 年加入 Quantics 市场团队。他拥有理论物理学和科学传播硕士学位,并拥有多年的在线科学传播和博客写作经验。
