作者:Eric · 发表于 2023年5月15日 · 更新于 2024年1月25日
文章目录
引言
如果您曾从事过实证工作,就会知道真实世界的数据很少会以干净、可直接用于建模的形式呈现。没有任何数据分析项目仅仅包括拟合模型和做出预测。在本篇博客中,我们将从头到尾走完一个完整的机器学习项目,为您提供在 GAUSS 中完成自己机器学习项目的基础,涵盖以下内容:
- 数据探索与清洗
- 训练集和测试集的划分
- 模型拟合与预测
- 基础特征工程
背景
我们的数据
今天我们将使用 Kaggle 的加利福尼亚房价数据集。该数据集基于 1990 年的人口普查数据构建。虽然它较老,但作为演示数据集非常出色,并在许多机器学习示例中广受欢迎。
该数据集包含在加利福尼亚州区块组级别测量的 10 个变量:
| 变量 | 描述 |
|---|---|
| longitude(经度) | 房屋向西距离的度量 |
| latitude(纬度) | 房屋向北距离的度量 |
| housing_median_age(房屋中位年龄) | 区块内房屋的中位年龄 |
| total_rooms(总房间数) | 区块内房间总数 |
| total_bedrooms(总卧室数) | 区块内卧室总数 |
| population(人口) | 区块内居住总人数 |
| households(家庭数) | 区块内家庭总数(一群居住在一个住宅单元内的人) |
| median_income(中位收入) | 区块内家庭的中位收入(以万美元计) |
| median_house_value(房屋中位价值) | 区块内家庭的中位房屋价值 |
| ocean_proximity(海洋距离) | 房屋相对于海洋/海的位置 |
GAUSS 机器学习
我们将使用全新的 GAUSS 机器学习(GML)库。这个库非常用户友好,提供易于使用的机器学习工具来实现基础机器学习模型。要使用这些工具,需要加载该库:
// Clear workspace and load library new; library gml; // Set random seed rndseed 8906876;
注意:我们设置了随机种子以确保结果可复现。
数据探索与清洗
加载 GML 后,我们准备导入和清洗数据。第一步是使用 loadd 过程将数据导入 GAUSS。
/* ** Import datafile */ load_path = "data/"; fname = "housing.csv"; // Load all variables housing_data = loadd(load_path $+ fname);
描述性统计
探索性数据分析使我们能够识别重要的数据异常,如异常值和缺失值。让我们先使用 dstatmt 过程查看标准的描述性统计:
// Find descriptive statistics // for all variables in housing_data dstatmt(housing_data);
这会打印出所有变量的统计汇总表。
-------------------------------------------------------------------------------------------------- Variable Mean Std Dev Variance Minimum Maximum Valid Missing -------------------------------------------------------------------------------------------------- longitude -119.6 2.004 4.014 -124.3 -114.3 20640 0 latitude 35.63 2.136 4.562 32.54 41.95 20640 0 housing_median_age 28.64 12.59 158.4 1 52 20640 0 total_rooms 2636 2182 4.759e+06 2 3.932e+04 20640 0 total_bedrooms 537.9 421.4 1.776e+05 1 6445 20433 207 population 1425 1132 1.282e+06 3 3.568e+04 20640 0 households 499.5 382.3 1.462e+05 1 6082 20640 0 median_income 3.871 1.9 3.609 0.4999 15 20640 0 median_house_value 2.069e+05 1.154e+05 1.332e+10 1.5e+04 5e+05 20640 0 ocean_proximity ----- ----- ----- <1H OCEAN NEAR OCEAN 20640 0
这些统计量使我们能够快速识别在拟合模型之前需要处理的几个数据问题:
total_bedrooms变量存在 207 个缺失观测值。- 许多变量显示出潜在的异常值,方差大且范围广。需要进一步探索。
缺失值处理
为了更好地了解如何处理缺失值,让我们分别检查有缺失值和没有缺失值的观测值的描述性统计。
// Conditional check for missing values e = housing_data[., "total_bedrooms"] .== miss(); // Get descriptive statistics for dataset with missing values dstatmt(selif(housing_data, e));
------------------------------------------------------------------------------------------------ Variable Mean Std Dev Variance Minimum Maximum Valid Missing ------------------------------------------------------------------------------------------------ longitude -119.5 2.001 4.006 -124.1 -114.6 207 0 latitude 35.5 2.097 4.399 32.66 40.92 207 0 housing_median_age 29.27 11.96 143.2 4 52 207 0 total_rooms 2563 1787 3.194e+06 154 1.171e+04 207 0 total_bedrooms ----- ----- ----- +INF -INF 0 207 population 1478 1057 1.118e+06 37 7604 207 0 households 510 386.1 1.491e+05 16 3589 207 0 median_income 3.822 1.956 3.824 0.8527 15 207 0 median_house_value 2.06e+05 1.116e+05 1.246e+10 4.58e+04 5e+05 207 0 ocean_proximity ----- ----- ----- <1H OCEAN NEAR OCEAN 207 0
通过目视检查,有缺失值的数据的描述性统计与没有缺失值的数据的描述性统计非常相似。此外,缺失值占总观测值的比例不到 1%。因此,我们将删除包含缺失值的行,而不是插补缺失值。
我们可以使用 packr 过程删除包含缺失值的行:
// Remove rows with missing values from housing_data housing_data = packr(housing_data);
异常值处理
删除缺失值后,让我们寻找其他数据异常值。数据可视化如直方图和箱线图是识别潜在异常值的好方法。首先,为所有连续变量创建一个直方图网格图:
/*
** Data visualizations
*/
// Get variables names
vars = getColNames(housing_data);
// Set up plotControl structure for formatting graphs
struct plotControl plt;
plt = plotGetDefaults("bar");
// Set fonts
plotSetFonts(&plt, "title", "Arial", 14);
plotSetFonts(&plt, "ticks", "Arial", 12);
// Loop through the variables and draw histograms
for i(1, rows(vars)-1, 1);
plotSetTitle(&plt, vars[i]);
plotLayout(3, 3, i);
plotHist(plt, housing_data[., vars[i]], 50);
endfor;
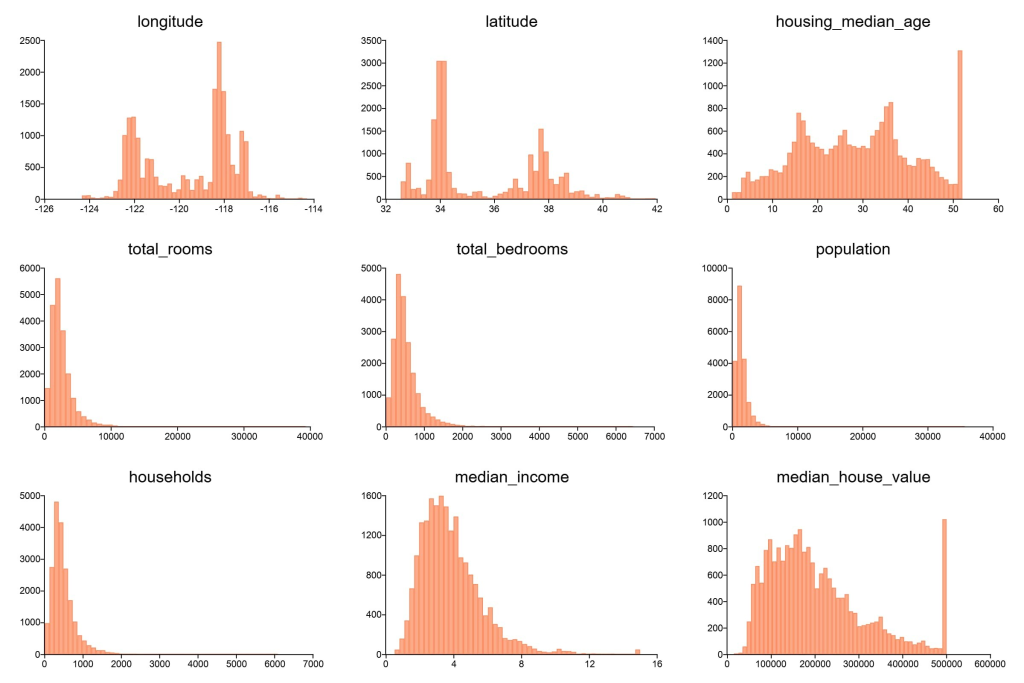
从直方图可以看出,几个变量存在异常值问题:
total_rooms变量,大部分数据分布在 0 到 10,000 之间。total_bedrooms变量,大部分数据分布在 0 到 2,000 之间。households变量,大部分数据分布在 0 到 2,000 之间。population变量,大部分数据分布在 0 到 100,000 之间。
这些变量的箱线图确认了异常值的存在。
plt = plotGetDefaults("box");
// Set fonts
plotSetFonts(&plt, "title", "Arial", 14);
plotSetFonts(&plt, "ticks", "Arial", 12);
string box_vars = { "total_rooms", "total_bedrooms", "households", "population" };
// Loop through the variables and draw boxplots
for i(1, rows(box_vars), 1);
plotLayout(2, 2, i);
plotBox(plt, box_vars[i], housing_data[., box_vars[i]]);
endfor;
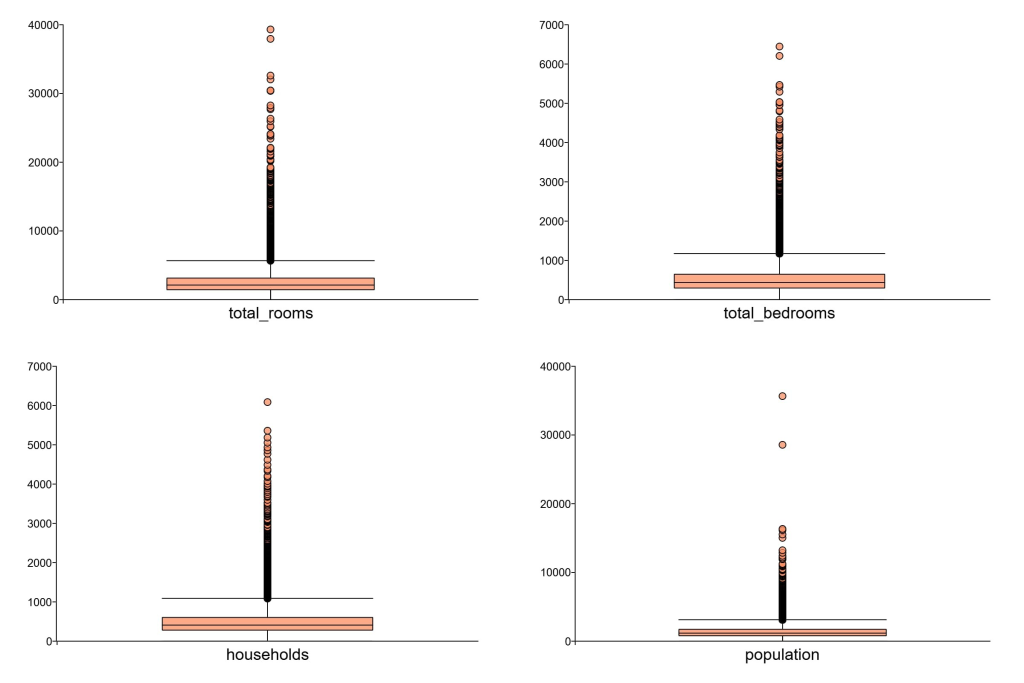
让我们过滤数据以消除这些异常值:
/* ** Filter to remove outliers ** ** Delete: ** - total_rooms greater than or equal to 10000 ** - total_bedrooms greater than or equal to 20000 ** - households greater than or equal to 2000 ** - population greater than or equal to 6000 */ mask = housing_data[., "total_rooms"] .>= 10000; mask = mask .or housing_data[., "total_bedrooms"] .>= 2000; mask = mask .or housing_data[., "households"] .>= 2000; mask = mask .or housing_data[., "population"] .>= 6000; housing_data = delif(housing_data, mask);
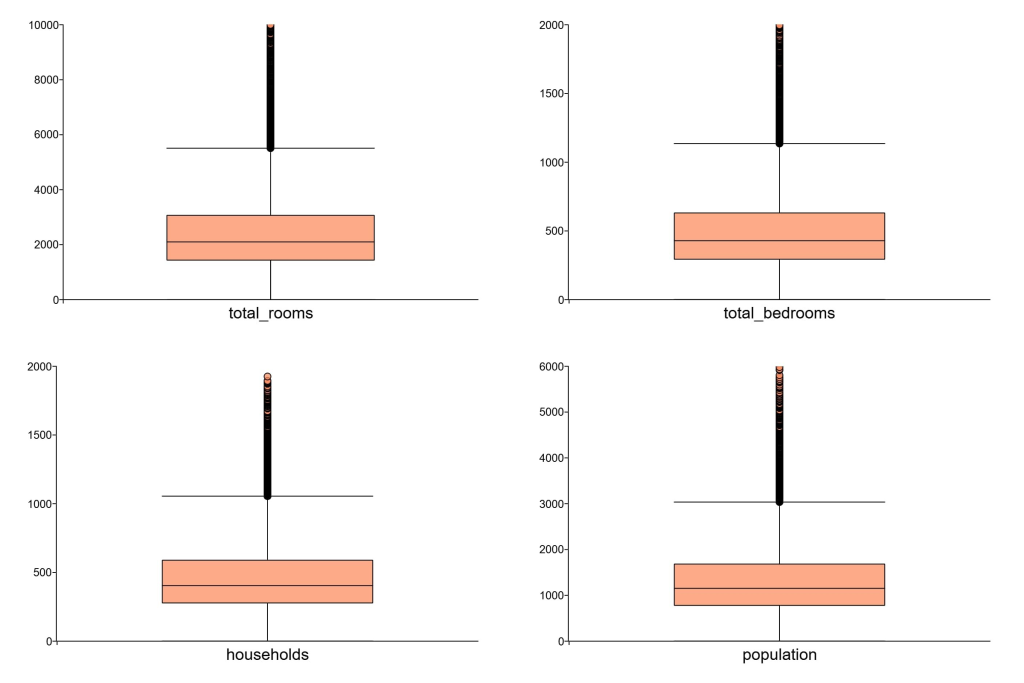
注意:我们采取了保守的异常值过滤方法,并未删除箱线图识别的所有异常数据点。
数据截断
直方图还指出了 housing_median_age 和 median_house_value 的截断问题。让我们进一步探究:
- 使用
modec确认这些是最频繁出现的观测值,为截断点提供证据。 - 统计这些位置上的观测值数量。
// House value mode_value = modec(housing_data[., "median_house_value"]); print "Most frequent median_house_value:" mode_value; print "Counts:"; sumc(housing_data[., "median_house_value"] .== mode_value); // House age mode_age = modec(housing_data[., "housing_median_age"]); print "Most frequent housing_median_age:" mode_age; print "Counts:"; sumc(housing_data[., "housing_median_age"] .== mode_age);
Most frequent median_house_value:
500001.00
Counts:
935.00000
Most frequent housing_median_age:
52.000000
Counts:
1262.0000
这些观测值合计占总观测值的约 10%。由于我们无法获得有关这些点的更多信息,将其从模型中删除。
// Create binary vector with a 1 if either
// 'housing_median_age' or 'median_house_value'
// equal their mode value.
mask = (housing_data[., "housing_median_age"] .== mode_age)
.or (housing_data[., "median_house_value"] .== mode_value);
// Delete the rows if they meet our above criteria
housing_data = delif(housing_data, mask);
特征修改
最后的数据清洗步骤是进行特征修改,包括:
- 将
median_house_value变量重新缩放到以万美元为单位(与median_income相同的尺度)。 - 为
ocean_proximity的类别生成虚拟变量。
首先,重新缩放 median_house_value:
// Rescale median income variable
housing_data[., "median_house_value"] =
housing_data[., "median_house_value"] ./ 10000;
接下来为 ocean_proximity 生成虚拟变量。使用 frequency 过程了解分类数据:
// Check frequency of ocean_proximity categories frequency(housing_data, "ocean_proximity");
Label Count Total % Cum. %
<1H OCEAN 8095 44.89 44.89
INLAND 6136 34.03 78.93
ISLAND 2 0.01109 78.94
NEAR BAY 1525 8.458 87.39
NEAR OCEAN 2273 12.61 100
Total 18031 100
从表中可以看出,ISLAND 类别非常小。将其从建模数据集中排除。现在使用 oneHot 过程创建虚拟变量:
/*
** Generate dummy variables for
** the ocean_proximity using one hot encoding
*/
dummy_matrix = oneHot(housing_data[., "ocean_proximity"]);
/*
** Build matrix of features
** Note we exclude:
** - ISLAND dummy variable
** - Original ocean_proximity variable
*/
model_data = delcols(housing_data, "ocean_proximity") ~
delcols(dummy_matrix, "ocean_proximity_ISLAND");
// Saved data matrix
saved(model_data, load_path $+ "/model_data.gdat");
数据划分
在机器学习中,通常使用不同的数据集来拟合模型和评估模型性能。由于机器学习模型的目标是为未见过的数据提供预测,使用测试集可以更真实地衡量模型的表现。要准备训练和测试数据,我们采取两个步骤:
- 分离目标变量
median_house_value和特征集。 - 使用
trainTestSplit将数据划分为 70% 训练集和 30% 测试集。
new;
library gml;
rndseed 896876;
/*
** Load datafile
*/
load_path = "data/";
fname = "model_data.gdat";
housing_data = loadd(load_path $+ fname);
/*
** Feature management
*/
// Separate dependent and independent data
y = housing_data[., "median_house_value"];
X = delcols(housing_data, "median_house_value");
// Split into 70% training data and 30% testing data
{ y_train, y_test, X_train, X_test } = trainTestSplit(y, X, 0.7);
拟合模型
完成数据清洗后,我们终于准备好拟合模型了。今天,我们将使用 LASSO 回归模型来预测目标变量。LASSO 是一种正则化形式,在经济和金融建模中取得了相对成功。它为处理线性模型中的高维性问题提供了数据驱动的方法。
模型拟合
要使用 LASSO 模型拟合目标变量 median_house_value,我们使用 GAUSS 机器学习库中的 lassoFit。
/*
** LASSO Model
*/
// Set lambda values
lambda = { 0, 0.1, 0.3 };
// Declare 'mdl' to be an instance of a
// lassoModel structure to hold the estimation results
struct lassoModel mdl;
// Estimate the model with default settings
mdl = lassoFit(y_train, X_train, lambda);
lassoFit 过程会打印模型描述和结果:
==============================================================================
Model: Lasso Target Variable: median_house_value
Number observations: 12622 Number features: 12
==============================================================================
===========================================================
Lambda 0 0.1 0.3
===========================================================
longitude -2.347 -1.013 -0.02555
latitude -2.192 -0.9269 0
housing_median_age 0.07189 0.06384 0.03977
total_rooms -0.001004 0 0
total_bedrooms 0.01165 0.006107 0.004828
population -0.004317 -0.003396 -0.001232
households 0.006808 0.005119 0
median_income 3.872 3.569 3.457
ocean_proximity__1H OCEAN -5.509 0 0
ocean_proximity_INLAND -9.437 -5.639 -6.575
ocean_proximity_NEAR BAY -7.083 -0.6395 0
ocean_proximity_NEAR OCEAN -5.198 0.6378 0.6981
CONST. -193.5 -82.98 3.451
===========================================================
DF 12 10 7
Training MSE 33.7 34.7 37.4
结果突出了 LASSO 的变量选择功能。当 λ=0(完整的最小二乘模型)时,所有特征都包含在模型中。当 λ=0.3 时,LASSO 回归删除了 12 个变量中的 4 个:latitude、total_rooms、ocean_proximity__1H OCEAN、ocean_proximity_NEAR BAY。正如预期,median_income 有较大的正向影响。
预测
我们现在可以使用 lmPredict 来测试模型在测试数据上的预测能力:
// Predictions predictions = lmPredict(mdl, X_test); // Get MSE testing_MSE = meanSquaredError(predictions, y_test); print "Testing MSE"; testing_MSE;
Testing MSE
33.814993
34.726144
37.199771
正如预期,这些值大多高于训练 MSE,但相差不大。λ 值最高的模型的测试 MSE 实际上低于训练 MSE,这表明我们的模型没有过拟合。
特征工程
由于模型没有过拟合,我们可以向模型添加更多变量。我们从当前特征的组合中创建一些新特征。这部分过程称为特征工程,可以对机器学习模型做出重大贡献。
首先为 total_rooms、total_bedrooms 和 households 生成人均变量。
/*
** Create per capita variables using population
*/
pc_data = housing_data[., "total_rooms" "total_bedrooms" "households"]
./ housing_data[., "population"];
// Convert to a dataframe and add variable names
pc_data = asdf(pc_data, "rooms_pc"$|"bedrooms_pc"$|"households_pc");
接下来创建一个表示 total_bedrooms 占 total_rooms 百分比的变量:
beds_per_room = X[.,"total_bedrooms"] ./ X[.,"total_rooms"]; X = X ~ pc_data ~ asdf(beds_per_room, "beds_per_room");
拟合与预测新模型
// Reset the random seed so we get the
// same test and train splits as our previous model
rndseed 896876;
// Split our new X into train and test splits
{ y_train, y_test, X_train, X_test } = trainTestSplit(y, X, 0.7);
// Set lambda values
lambda = { 0, 0.1, 0.3 };
// Declare 'mdl' to be an instance of a
// lassoModel structure to hold the estimation results
struct lassoModel mdl;
// Estimate the model with default settings
mdl = lassoFit(y_train, X_train, lambda);
// Predictions
predictions = lmPredict(mdl, X_test);
// Get MSE
testing_MSE = meanSquaredError(predictions, y_test);
print "Testing MSE"; testing_MSE;
==============================================================================
Model: Lasso Target Variable: median_house_value
Number observations: 12622 Number features: 16
==============================================================================
===========================================================
Lambda 0 0.1 0.3
===========================================================
longitude -2.495 -1.008 0
latitude -2.36 -0.9354 0
housing_median_age 0.0808 0.07167 0.04316
total_rooms -0.0001714 0 0
total_bedrooms 0.005301 0.001517 0.0008104
population -0.0004661 0 0
households -0.001611 0 0
median_income 3.947 4.011 3.675
ocean_proximity__1H OCEAN -5.171 0 0
ocean_proximity_INLAND -8.635 -4.963 -6.235
ocean_proximity_NEAR BAY -6.966 -0.875 0
ocean_proximity_NEAR OCEAN -5.219 0.2927 0.1798
rooms_pc 2.678 0.1104 0
bedrooms_pc -11.68 0 0
households_pc 22.23 21.47 20.23
beds_per_room 33.03 17.03 8.029
CONST. -221.9 -95.55 -3.059
===========================================================
DF 16 11 7
Training MSE 31.6 32.5 34.3
Testing MSE
31.505169
32.457936
34.155290
在所有的 λ 值下,训练和测试 MSE 都有所改善。在新变量中,households_pc 和 beds_per_room 似乎具有最强的影响。
扩展与延伸
我们使用了线性回归模型 LASSO 来建模房屋价值。这个选择是临时的,还有许多替代方法和扩展可以帮助改进预测。例如:
- 使用聚类或 K 近邻来捕捉更多位置信息。
- 使用主成分分析捕捉特征的变异,然后估计中位房屋价值与主成分之间的线性关系。
- 使用 随机森林模型,这对于表格数据集通常能提供很好的准确性。
- 将房屋价值分成多个区间,进行分类而非回归。
结论
在今天的博客中,我们看到了数据探索和清洗在开发机器学习模型中的重要作用。我们很少能获得可以直接输入模型的数据。最佳实践是花时间进行数据探索和清洗,因为任何机器学习模型的可靠性都取决于其数据的质量。
