创建新文件
要开始新的电子表格,请单击File > New或单击新建文件工具按钮。
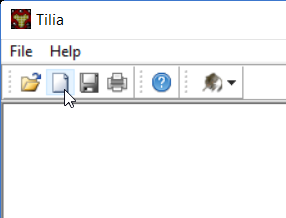
第一次创建新电子表格时,它通常如下所示:
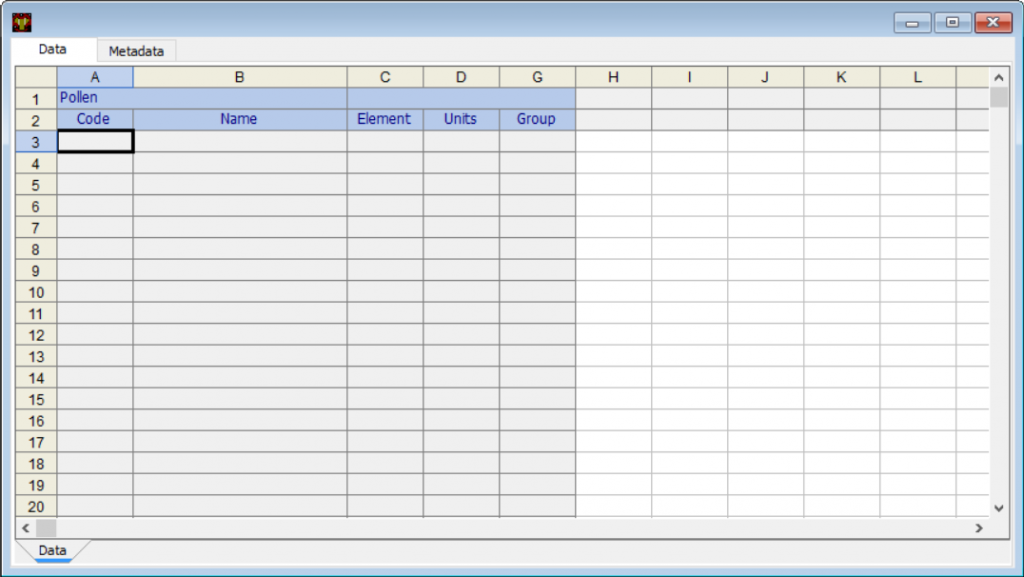
请注意,E 和 F 列是隐藏的。要显示所有列,请单击Tools > Options:
这将显示Spreadsheet Options(电子表格选项)对话框。
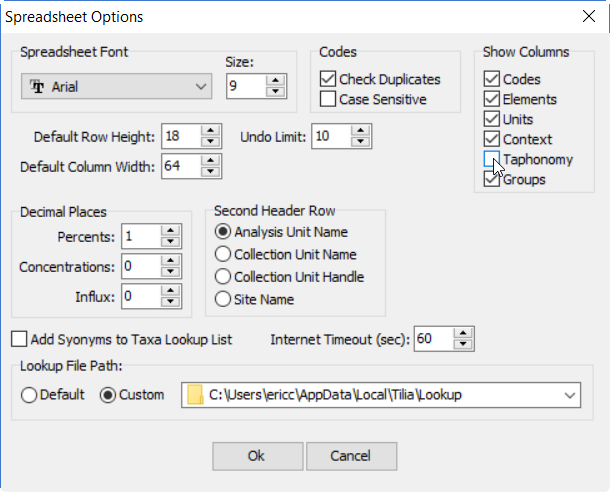
要显示所有列,请选中Show Columns 下的所有复选框。
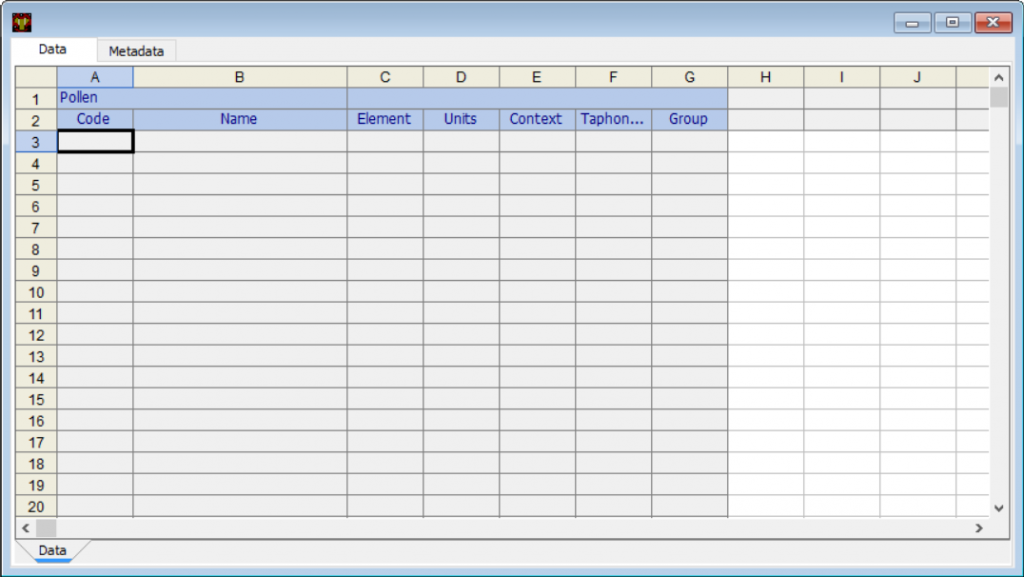
现在所有列都可见:
数据集类型
单元格 A1 中的文本指示数据集的类型。虽然此条目不是必需的,但它确实会影响使用分类查找文件的自动数据输入(见下文)。通过单击单元格并从下拉菜单中选择来选择数据集类型:
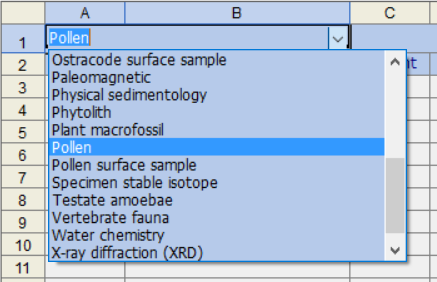
这些数据集类型在Neotoma Paleoecology Database中定义。
默认数据集类型是Pollen,但您的电子表格将使用您上次保存的文件的数据集类型打开。
变量
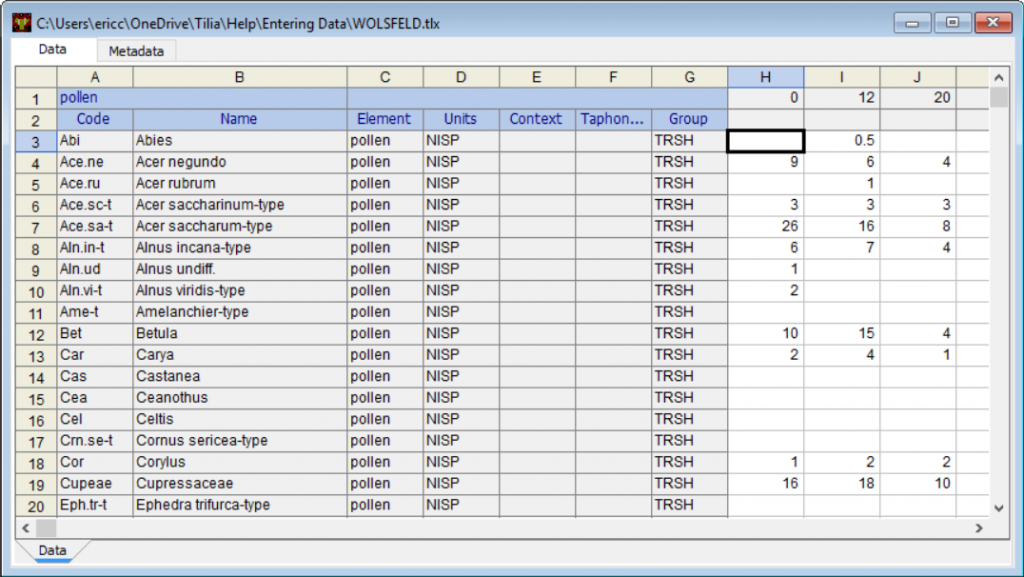
在 Tilia 电子表格中,行是变量,列是样本。变量包括几个组件:Code(代码), Name(名称), Element(元素), Units(单位), Context(上下文), Taphonomy(上下文), 和 Group(组)。制作地层图只需要代码和名称;但是,Group通常非常有用。Neotoma 古生态数据库中的变量也需要Element 和Units。
Context和Taphonomy使用较少,稍后将讨论,因此这些列现在将被隐藏。
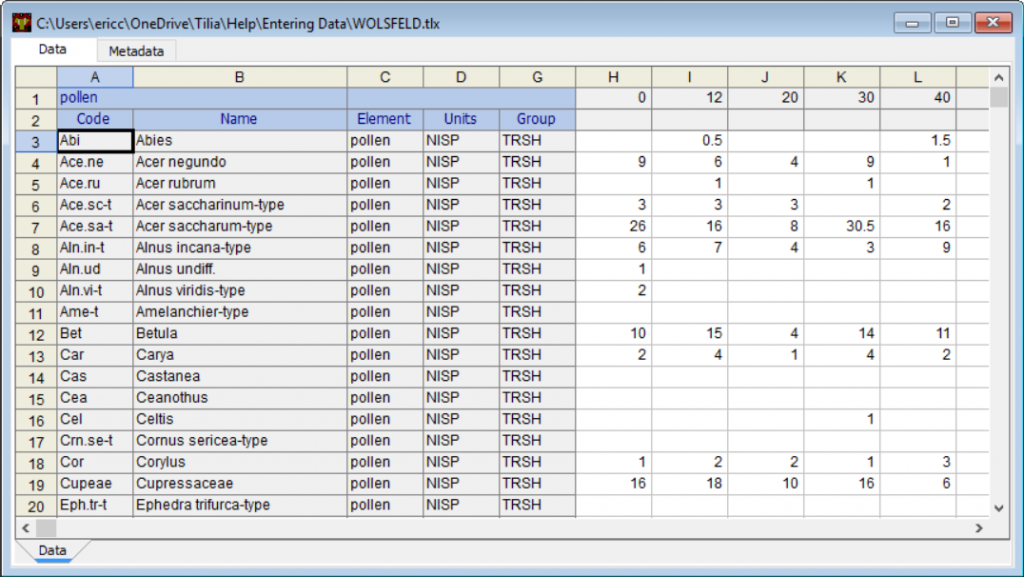
Name是分类单元的名称。
Code是每个分类单元的唯一代码。代码可以是您想要的任何东西;唯一的要求是它们在电子表格中是唯一的。此示例中显示的代码是Neotoma 古生态数据库中使用的代码。
Element是标识的元素。由于这是一个花粉数据集,大多数元素将是pollen或spore。然而,其他的也是可能的,例如stomate。其他数据集类型可能有多种元素。例如,植物大化石数据集可能有leaf, needle, seed, bud scale(芽鳞)等。元素可以可选地出现在图表中,例如Picea needle、 Picea seed。
Units是变量的度量单位。NISP = 已识别样本数,换言之,计数。
Group是任何分组方案的代码。此处显示的代码是来自Neotoma Paleoecology Database的花粉数据集的默认代码:
| 代码 | 团体 |
| TRSH | 树木和灌木 |
| PALM | 棕榈树 |
| MANG | 红树林 |
| UPHE | 高地草药 |
| SUCC | 多肉植物 |
| VACR | 血管隐球菌 |
| UPBR | 高地苔藓植物 |
| AQVP | 水生维管植物 |
| AQBR | 水生苔藓植物 |
| FUNG | 菌类 |
| ALGA | 藻类 |
| UNID | 未知和不确定 |
没有必要非使用这些代码;您可以使用任何您喜欢的代码。但是,如果这些代码适合您的数据,它们会使百分比的计算更容易一些。
样本
样本从 H 列开始。第 1 行是样本深度。第 2 行是样本名称。对于地层图,您必须有深度。示例名称是可选的,它们可能会显示在图表上。表面样本通常有名称。下面的示例是Pollen surface sample(花粉表面样本)数据集。深度是伪深度,它将设置图表上样本之间的间距。
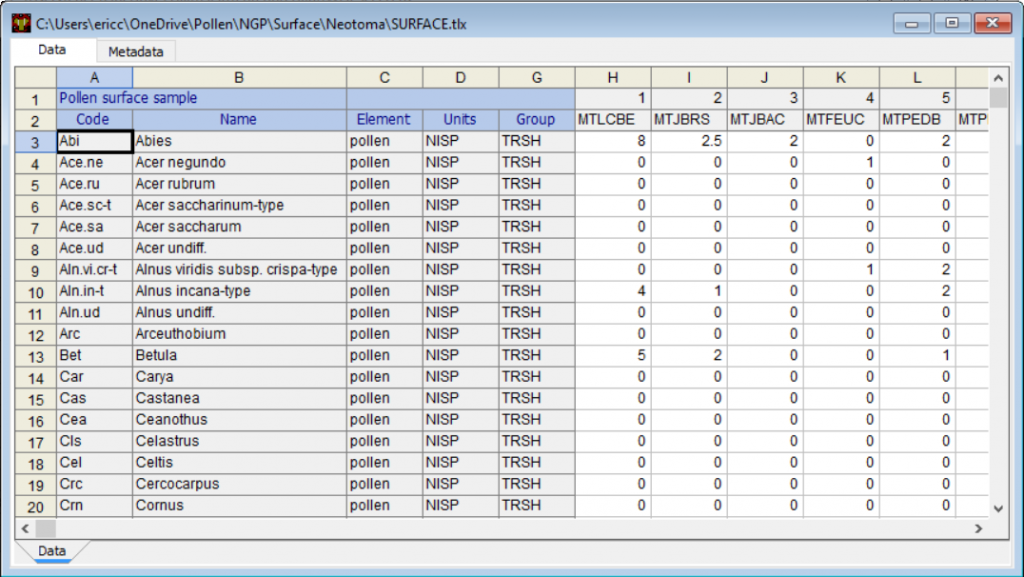
数据
实际数据从单元格 H3 开始。在到目前为止的所有示例中,零值可以用单元格中的 0 或将单元格留空来表示。但是,如果单元格留空,系统将询问您是否应将它们转换为零以用于图表。在某些情况下,空白单元格可能表示没有数据而不是零值。例如,如果花粉和烧失量 (LOI) 数据在同一个电子表格中,则某些样本深度可能有 LOI 数据而没有花粉数据,在这种情况下,花粉单元格应为只有 LOI 的样本深度留空数据,花粉样本应输入零值。
变量查找文件
分类单元名称可以直接输入、从另一个电子表格复制和粘贴,或从外部查找文件中选择。Tilia 与许多变量查找文件一起分发,这些文件可能会从 Neotoma Paleoecology Database定期更新。要打开查找文件,请单击Tools > Variable Lookup或单击变量查找工具按钮。
这将显示“ Variable Lookup Files”对话框:
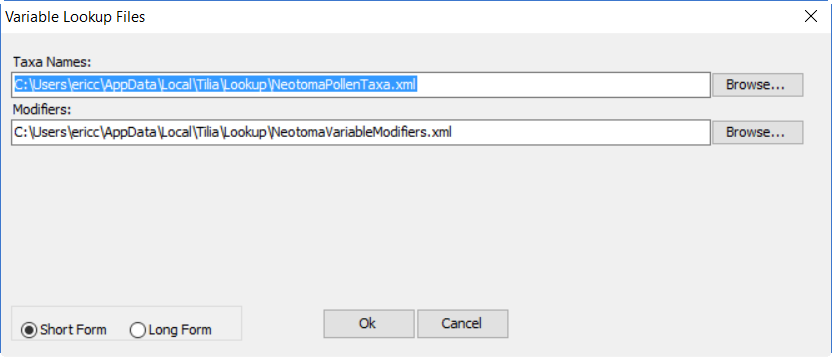
您可以通过选择 Browse… 按钮来选择查找文件。默认情况下,变量查找文件存储在目录中:
C:\Users\ [用户名]\AppData\Local\Tilia\Lookup
查找文件都具有 .xml 扩展名,例如 NeotomaPollenTaxa.xml。
修饰符(元素、单位等)存储在单独的文件中,该文件通常始终是默认文件名 NeotomaVariableModifiers.xml。
打开变量查找文件后,可以从下拉列表中选择分类名称。您也可以开始输入一个名字,匹配的名字就会出现。如果名称不在列表中,您可以输入新名称。
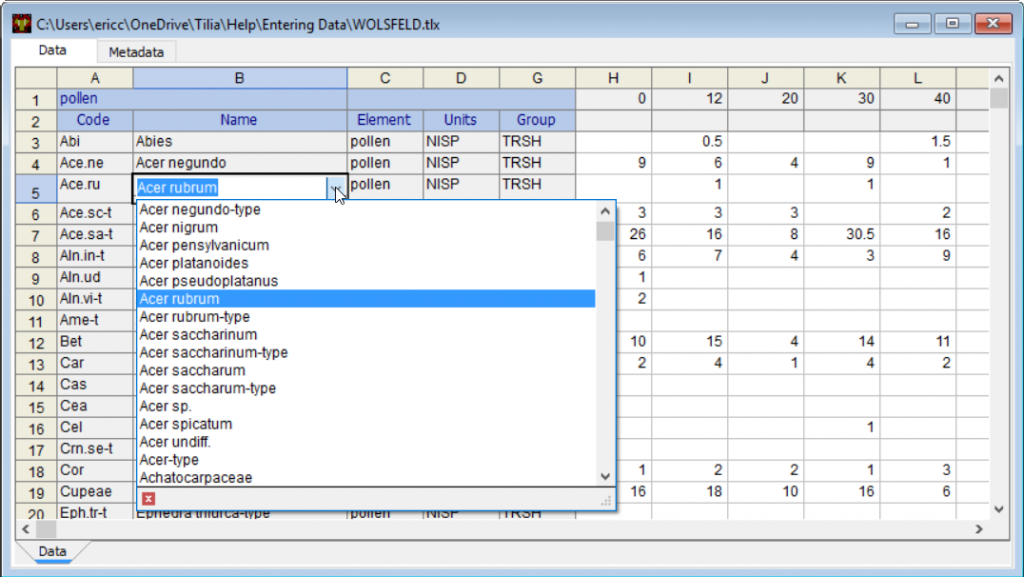
查找文件中的名称来自 Neotoma Paleoecology Database。因此, NeotomaPollenTaxa.xml 查找文件具有出现在 Neotoma花粉数据集中的所有名称。
如果您从下拉列表中选择一个分类单元, 将自动输入代码 和默认组。如果分类单元在数据库中只有一个元素,那么它也将被输入。否则,也可以从下拉列表中选择元素:
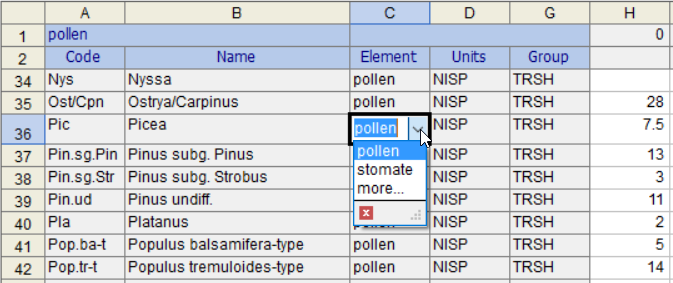
列出的元素是当前在 Neotoma 中用于 花粉 数据集类型的元素。more … 选择表示在另一种数据集类型中存在更多元素,在本例中为plant macrofossil(植物大化石)数据集。如果单击 more…,则会出现这些附加元素。
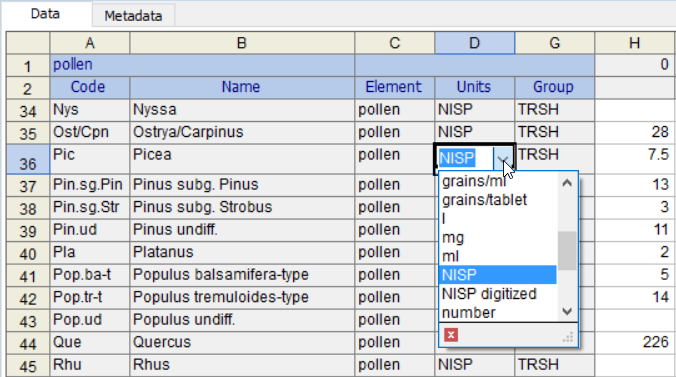
也可以从下拉列表中选择单位。将列出数据集类型的所有单位:
更新变量查找文件
要从Neotoma更新本地 Tilia 查找文件,请单击Neotoma > Lookup > New Taxa Lookup File。
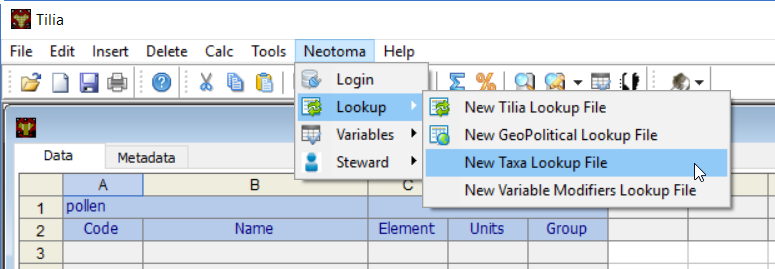
这将显示Write New Taxa Lookup File对话框:
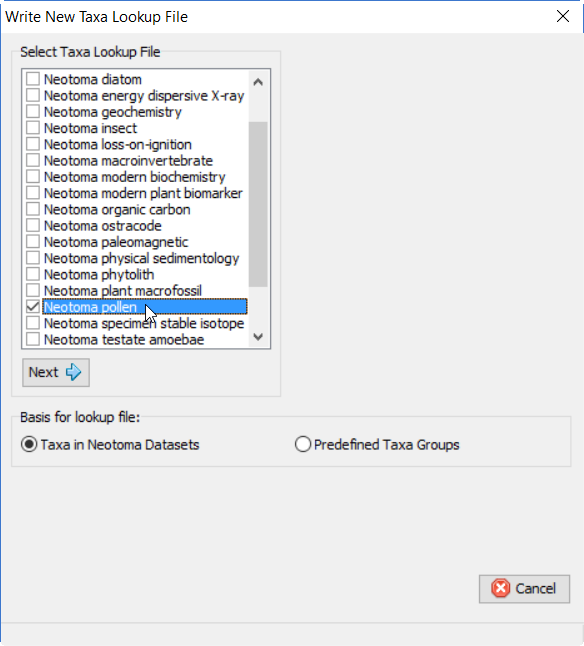
检查您要更新的查找文件,在本例中是花粉查找。单击Next按钮。
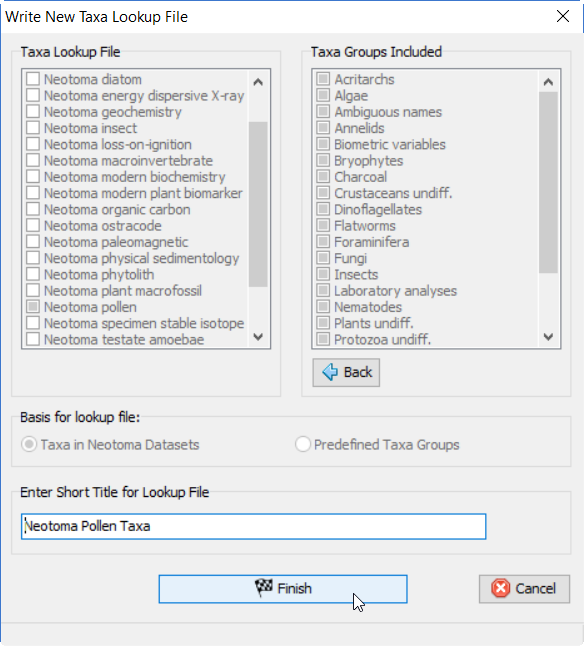
右侧将出现一个面板,其中包含将包含在此查找文件中的分类群。此列表无法编辑;它只是提供信息。单击Finish按钮以写入新文件。系统将询问您是否要替换现有的查找文件。通常,您会单击Yes。
从 Excel 导入数据
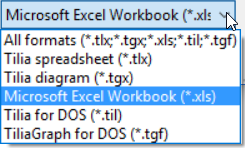
可以通过打开 .xls 文件(不是 .xlsx)或通过复制和粘贴从 Excel 导入数据。要打开 .xls 文件,请单击File > Open,然后在打开文件对话框的右下角,选择Microsoft Excel Workbook (*.xls)以显示可用文件。在尝试在 Tilia 中打开之前,确保文件未在 Excel 中打开。
Tilia 为单元格读取 Excel 文件单元格。Tilia 中的隐藏列仍可在 Excel 文件中识别。因此,Excel 文件的格式必须与 Tilia 文件完全相同,如下所示:
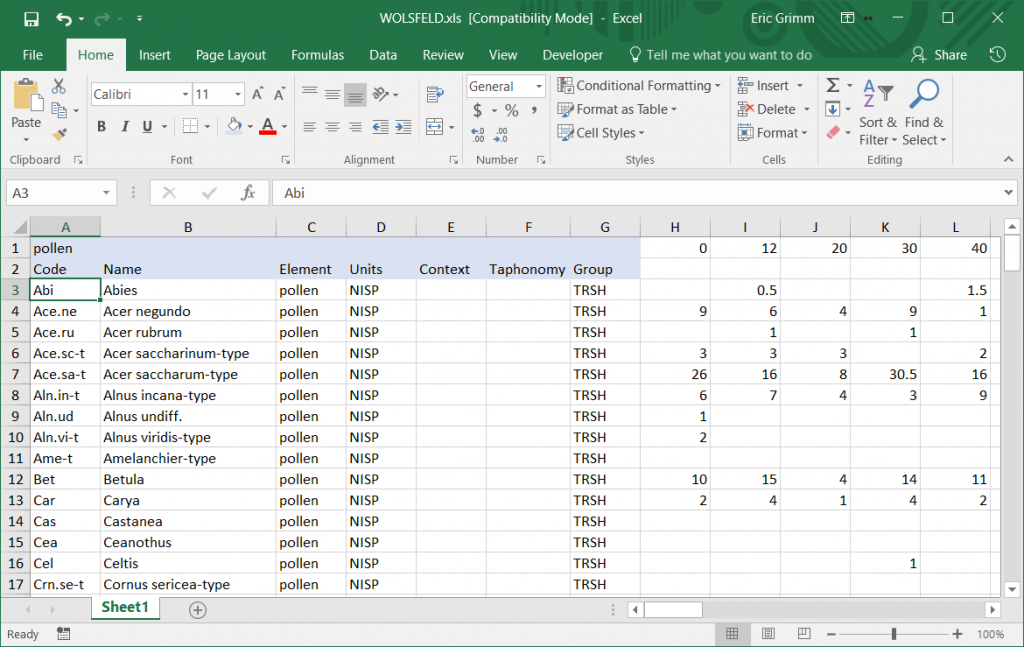
当 Tilia 读取工作表时,蓝色的单元格将被忽略。系统将提示您要导入哪个工作表。
通常,从 Excel 复制和粘贴数据比读取文件更容易,尽管您可能需要先转置工作表,以便列是样本,行是变量。只需将分类单元名称复制并粘贴到 B 列,从单元格 A3 开始,将样本深度复制到第 1 行,从单元格 H1 开始,数据从单元格 H3 开始。复制和粘贴是从 .xlsx 文件导入数据的唯一方法,而不是保存到 .xls 文件。
