数据集大小的粗略计算是
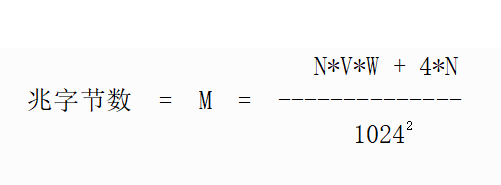
这里
N = 观测值数
V = 变量数
W = 变量的平均字节宽度
在近似 W 时,记住

假设您有一个包含 20,000 个观测值的数据集。 该数据集包含

因此,变量的平均宽度为 W = 58/20 = 2.9 字节。
您的数据集的大小是

这个结果稍微低估了数据集的大小,因为我们没有包含任何可能添加到数据中的变量标签、值标签或注释。 这不算多。 例如,假设您为所有 20 个变量添加了变量标签,并且标签文本的平均长度为 22 个字符。 这将总计 20*22=440 字节或 440/10242=.00042 兆字节。
公式说明
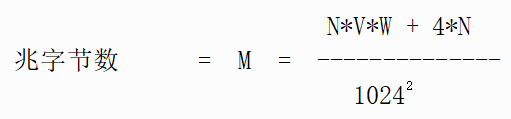
N*V*W 当然是数据的总大小。 为此,我们添加了 4*N,因为 Stata 为每个观测值秘密存储了一个 4 字节的指针。
分母中的 1,0242将结果重新调整为兆字节。 是的,结果除以 1,0242,即使 1,0002 = 一百万。
计算机内存以二进制递增。 尽管我们认为 k 代表千,但在计算机业务中,k 确实是一个“二进制”千,210 = 1,024。
兆字节是二进制的百万——二进制 k 的平方:
1 MB = 1024 KB = 1024*1024 = 1,048,576 bytes
对于便宜的内存,我们有时会谈论千兆字节。 以下是二进制千兆的推演:
1 GB = 1024 MB = 10243 = 1,073,741,824 bytes
