PLS-SEM 和自举(bootstrap)问题
为什么 SmartPLS 中的某些或所有参数会导致结果为 n/a?
如果没有可能的解,您将收到参数结果的 n/a(例如,路径系数、载荷、权重等)。这个问题通常发生在执行自举例程并且一个或多个自举样本导致无效的解时(即,无法为模型或其某些部分计算解)。因此,结果表显示有问题的参数为 n/a。一旦所有 bootstrap 样本都出现 n/a 结果,就无法计算 bootstrap 分布的均值和标准差。因此,结果表显示了这些结果的不适用。
以下屏幕截图说明了该问题:
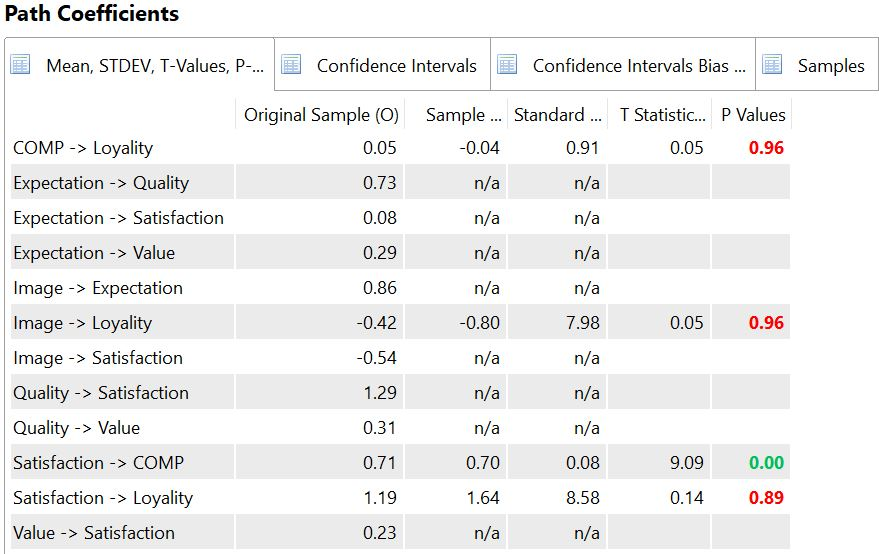
注意:要复制上面显示的问题,请运行 SmartPLS 3,打开 ECSI 模型,选择具有 98 个观测值的数据集,并使用默认设置启动一致的bootstrap 。
1) 为什么没有过滤掉无效的bootstrap 解决方案?
不可接受的解总是表明数据或模型存在问题。缺乏结果使研究人员意识到了这个问题。有了这些信息,用户可以解决问题,以便创建适当的解决方案。
此外,过滤掉不可接受的解会扭曲对bootstrap 生成的样本分布的估计。结果只会考虑“好的”bootstrap 解。因此,bootstrap 程序的结果可能会低估参数估计的实际可变性(例如其标准误差)。这可能导致模型和数据的错误推断(例如,重要性评估中的错误)。
2) 潜在的问题是什么?
当您使用一致的 PLS-SEM (PLSc-SEM) bootstrap 时:
一致的 PLS-SEM (PLSc-SEM) 算法对反射结构的相关性进行校正,以使结果与因子模型一致(Dijkstra 和 Henseler,2015;Dijkstra 和 Schermelleh-Engel,2014)。因此,它使用了一种特定于 PLS-SEM 上下文的新可靠性度量,称为 rho_A(Dijkstra 和 Henseler,2015)。众所周知,这种可靠性统计在 PLS-SEM 中是一致的(即,它在公因子模型的共同规律性条件下以及当样本量增加到无穷大时接近真实可靠性)。但是,它可能会在较小的样本量和公因子假设不成立时产生不可接受的解(例如,构造遵循复合模型;例如,Rigdon 2016;Rigdon、Sarstedt 和 Ringle,2017;Sarstedt 等人 2016)。在这些情况下,可靠性估计可能超出 0 到 1 的允许范围(Takane 和 Hwang,2018 年)。如果它是负数,则校正根本不起作用,因为它需要取 rho_A 的平方根,而这不是为负值定义的。但在校正相关性后,当得到的校正相关性超出区间 -1 到 1 时,极端正值也可能导致估计问题。
该问题还与 CB-SEM 中的 Haywood 案例进行了比较,其中该方法估计了负方差(这当然是不可能的)。
PLSc 对公因子模型假设非常严格。偏离这些假设可能会导致估计问题,从而导致不可接受的解决方案。因此,研究人员可能会重新审视反射结构的公因子模型假设。如果合适的话,可以将构造物作为复合物进行处理和估计。但是,在假设公因子模型时,避免这些问题的简单建议是使用更大的样本量。
当您使用标准 PLS-SEM bootstrap 时:
与使用 PLSc-SEM 相比,使用标准 PLS-SEM 算法出现不可接受的解决方案的频率要低得多。这个问题的发生几乎总是与(a)模型中几乎完美的共线性或(b)零方差的变量有关。
这两个问题可能不会出现在原始数据上,但可能会在bootstrap 过程中出现。后者是一个随机过程,它从原始样本中提取观察结果而不进行替换,以创建bootstrap 子样本。所有子样本的参数估计结果代表样本分布。然而,由于bootstrap 的随机性,一些子样本可能会表现出极端的特征。
例如,如果仅绘制完全共线的那些观察值,则整个样本上的强多重共线性问题可能会变成完全共线性。在这些情况下,您要么需要解决共线性问题,要么尝试增加样本量。
同样,如果模型包含方差接近于零的变量(即几乎每个受访者的值相同),则可能会出现不可接受的解。特别是,如果一个变量包含非常相同的响应,则可以仅绘制具有相同值的观测值,从而导致该子样本中该变量的方差为零。PLS-SEM 中数据的标准化还包括将值除以变量的方差。除以零会导致不可接受的解。如果您有一个非常同质的组,其中一些变量的方差很小,或者如果您将分组变量作为指标包含在模型中并运行多组分析,则可能会发生此事件。分组后,这个变量只有相同的值,因此没有方差。此外,虚拟变量(例如. 零一变量),其中一个类别非常罕见,可能会导致此类bootstrap 问题。此外,小样本量会使问题变得更加严重,其中抽取此类样本的可能性高于大样本量。在这两种情况下,您都应该检查模型中的低方差变量,如果可能,排除它们或增加样本量。
当您使用 PLS-SEM(或 PLSc-SEM)拟合指数时:
一些 PLS-SEM 拟合指数在模型评估的一般适用性方面存在局限性。例如,它们没有为使用重复指标的模型定义(例如,在 PLS-SEM 中估计高阶模型时)。这种类型的模型系列在指标相关矩阵中包含 1 的完美相关性(因为同一个指标被使用两次并且与自身完美相关)。在这种情况下,一些拟合指数的计算是不可能的。
参考
- Dijkstra, T. K., and Henseler, J. (2015). Consistent Partial Least Squares Path Modeling, MIS Quarterly, 39(2): 297-316.
- Dijkstra, T. K., and Schermelleh-Engel, K. (2014). Consistent Partial Least Squares for Nonlinear Structural Equation Models, Psychometrika, 79(4): 585-604.
- Takane, Y., & Hwang, H. (2018). Comparisons Among Several Consistent Estimators of Structural Equation Models. Behaviormetrika, 45(1), 157-188.
- Sarstedt, M., Hair, J. F., Ringle, C. M., Thiele, K. O., & Gudergan, S. P. (2016). Estimation Issues with PLS and CBSEM: Where the Bias Lies!. Journal of Business Research, 69(10), 3998-4010.
- Rigdon, E. E., Sarstedt, M., & Ringle, C. M. (2017). On Comparing Results from CB-SEM and PLS-SEM. Five Perspectives and Five Recommendations. Marketing ZFP, 39(3), 4-16.
- Rigdon, E. E. (2016). Choosing PLS Path Modeling as Analytical Method in European Management Research: A Realist Perspective. European Management Journal, 34(6), 598-605.
请始终引用 SmartPLS 的使用!
Ringle, Christian M., Wende, Sven, & Becker, Jan-Michael. (2015). SmartPLS 3. Boenningstedt: SmartPLS. Retrieved from https://www.smartpls.com
